November 18, 2025
•
5
min read
At Datumo, our Human Resources (HR) team sift through dozens - sometimes hundreds - of resumes every day, arriving in all kinds of unstructured formats: PDFs, DOCX files, even images. Manually reviewing and extracting information from these documents is a slow, tedious task and more often than not error-prone. We needed a smarter, faster way to turn that unstructured resume data into clean, structured, and searchable information - fueling reliable recruiting analytics and freeing up valuable time for more strategic work.
To solve this, we designed and implemented a resume parsing API and processing pipeline powered by Natural Language Processing (NLP) techniques and Large Language Models (LLMs). Combined with BigQuery, this system delivers scalable, automated extraction of structured data from unstructured resumes - transforming, laying the groundwork for smarter, faster talent operations.
Resumes come in many shapes and forms - PDFs, creative designs, scanned documents or even plain text. This wide variety introduces challenges in processing unstructured resume data, especially when the structure or design affects visibility of key information.
Humans tend to favor visually polished or professionally designed resumes, often subconsciously associating visual appeal with competence. This introduces bias into the resume screening process. In contrast, our resume parsing system, powered by Large Language Models (LLMs) and structured prompts, extracts key information from resumes and consolidates it into a standardized, tabular format - regardless of layout or design.
By automating this parsing step, we reduce the influence of subjective formatting preferences and support more consistent, equitable human review based on skills, experience, and qualifications.
In today’s recruiting environment, time and scale play a major factor as companies can receive hundreds, sometimes thousands of resumes for a single open role, it is like searching for a needle in a haystack. Manual processing of large-scale resume data is no longer feasible, as recruiters can spend hours or days just reading through resumes, usually with limited consistency or insights into the decision-making process.
To handle bulk processing of applications efficiently, a more automated solution is necessary. Our resume parsing API processes incoming resumes continuously - extracting structured, relevant data from all resumes and enabling near real-time filtering, searching, and shortlisting.
By combining automated resume parsing with cloud-based data pipelines, we can process thousands of resumes per day without adding headcount, while ensuring that each resume is parsed consistently and presented in a standardized format for review. This is a major improvement over traditional manual screening.
For any HR decision-making process to be effective, the accuracy and consistency of extracted resume data is absolutely crucial. Whether it's a job title, employment dates, or listed skills, even small inconsistencies can mislead recruiters and lead to incorrect candidate ranking, filtering, or false negatives.
We designed our system to accurately extract data from unstructured data formats - regardless of layout, formatting, or structure. This includes validation rules for:
With high-quality, structured resume parsing output, recruiters can trust that they’re making decisions based on complete and consistent data - not formatting quirks or copy-paste errors. This creates a level playing field, increases recruitment efficiency, and ensures the foundations are in place to introduce more advanced screening tools in the future.
Automating resume parsing isn't just about speed - it's about creating long-term value by turning unstructured information into structured, machine-readable data. Once resume content is parsed and normalized, it becomes significantly easier to build useful tools and workflows around it.
With structured resume parsing, we unlock a wide range of downstream applications, including:
While we are predominantly focused on data extraction and normalization, our structure easily allows for the integration of future innovations - from AI-driven resume evaluations and job matching engines to automated candidate insights. It’s a forward-looking investment that transforms how talent is sourced and managed.
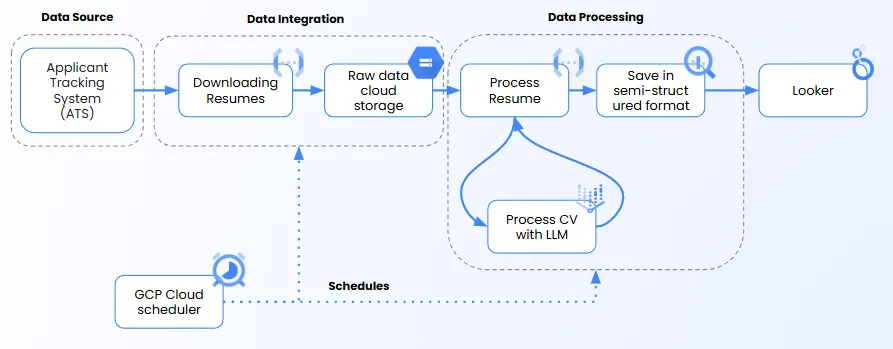
Our architecture connects directly to our Applicant Tracking System (ATS), where candidates submit resumes in various formats - including PDFs, DOCX files, and even images. The wide variety of resumes presents challenges in resume parsing, requiring a combination of traditional extraction and advanced Optical Character Recognition (OCR) to handle all cases reliably.
A scheduled job (via GCP Cloud Scheduler) triggers resume downloads using Google Cloud Function from the ATS. These files are stored in a raw format in cloud storage, where we differentiate between formats:
To avoid unnecessary processing and duplication, we also store resume metadata, including file hashes and timestamps. This allows us to detect and skip duplicate files efficiently, preserving compute resources and ensuring the accuracy of downstream data pipelines.
Once files are stored in cloud storage, a resume processing function is triggered. This step handles:
After detecting the file type using its MIME type, we apply format-specific logic to extract the resume text content. This is a critical stage of the resume parsing pipeline, as it converts resumes from diverse sources into machine-readable formats suitable for further processing.
a) PDF and DOCX
We use document parsers to extract raw text from resumes submitted as PDFs or Word documents. In addition to basic text, we also preserve useful metadata like embedded URLs e.g., LinkedIn profiles, portfolios.
b) Images and Scanned Documents
For image-based resumes - including photos, scans, and screenshots - we apply Optical Character Recognition (OCR) using OpenCV. This allows us to convert unstructured visual data into structured text, even in cases where the resume was poorly scanned, stylized or even made into a GIF.
Because resumes often vary in design, layout, and structure, robust resume extraction is essential to maintain parsing accuracy across different formats. This step ensures that every candidate’s resume - regardless of how it was submitted - can be processed and passed to the next stage in a normalized, consistent format.
Once we have clean, extracted resume content (text), it’s formatted into a structured prompt and sent to a Vertex AI endpoint.
Unlike traditional rule-based resume parsing tools, which rely heavily on layout patterns or keyword matching, LLMs excel at interpreting unstructured data - including unformatted resumes or those written in free text. This allows us to extract meaning and context from resumes that would otherwise be difficult to parse using conventional methods.
To ensure consistent output, we use prompt engineering to define a clear schema. The LLM is instructed to return a strict JSON structure with resume attributes like:
This approach allows our resume parsing API to produce a structured output that can be validated, stored, and queried reliably.
Even though the LLM returns structured JSON, we do not assume the output is always complete or correct. Large Language Models can occasionally omit fields, return incorrect types, or introduce inconsistencies - especially when processing highly unstructured resumes.
To ensure data quality and consistency, we validate every response using a strict Pydantic schema. This includes:
Using Pydantic allows us to perform structural and semantic validation early in the pipeline, before the data reaches BigQuery or any downstream system. This reduces the risk of bad data affecting dashboards, filters, or decision-making logic.
Resumes that fail validation are excluded from the batch, logged for later inspection, and optionally routed to a retry queue or manual review process. This validation step ensures that only high-quality, structured resume data is stored, which increases confidence in the entire automated screening process.
Once each resume has been parsed and validated, the results are loaded into BigQuery in batches. The dataset is added to a structured table with a predefined schema, as shown below.
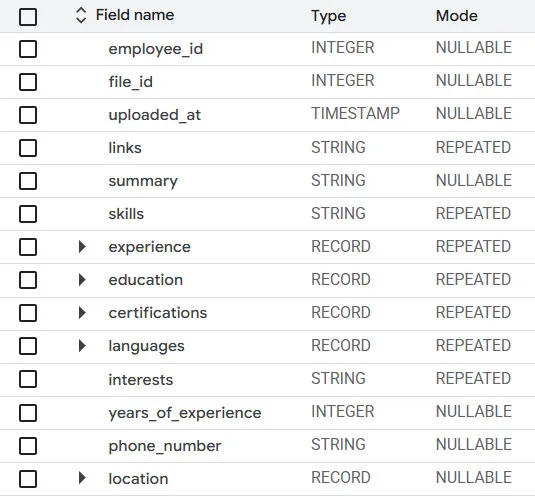
Storing resume data in BigQuery gives us:
While our current system focuses primarily on resume parsing and normalization, this structured format supports downstream use such as:
In summary, once resumes are ingested into BigQuery, they become reliable, structured data - enabling faster and more consistent decision-making within the recruitment process.
To demonstrate the pipeline in practice, the following section presents a simplified end-to-end example of a real resume submitted through the ATS:

View the full document on Scribd
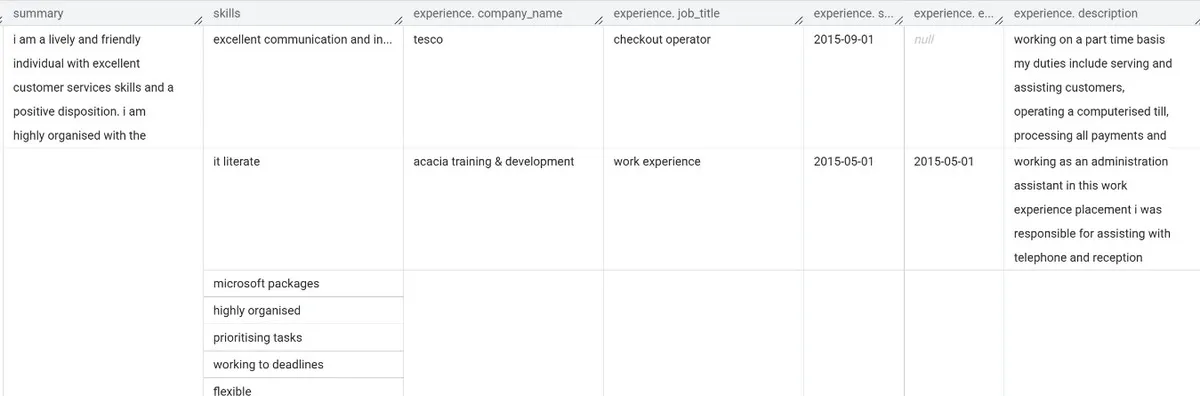
This file is downloaded to our cloud storage bucket, classified as a PDF, and passed through the parsing pipeline. The resume content is converted into structured JSON using an LLM. After validation, the final result is stored in BigQuery as presented in the picture below.
Developing an automated resume parsing pipeline using LLMs presented several technical and operational challenges. Below we break down the key issues we faced and the solutions we implemented to make our system more robust, reliable, and scalable.
Challenge:
Resumes arrive in every imaginable format - from professionally structured PDFs to scanned resumes with creative layouts. Even screenshots, GIFs, and photos are regularly received. Some resumes also contain multiple languages or non-standard encodings, which further complicate data extraction.
Our Approach:
This preprocessing ensures that no resume is discarded prematurely, and even imperfect inputs can often be recovered and parsed effectively.
Challenge:
Getting consistent, structured output from an LLM depends heavily on how the prompt is designed. Early prompts frequently returned inconsistent results - missing fields, improperly nested structures, or verbose outputs.
Our Approach:
Challenge:
Even with a solid prompt, LLMs can produce output that is structurally valid but semantically flawed. For example:
Our Approach:
By treating the LLM as an intelligent but fallible component, we built guardrails that prevent bad data from contaminating downstream systems. In case of bigger hallucinations, we always keep humans in the loop.
Problem:
One key reason for adopting LLM-based parsing was to reduce human bias - but it’s equally important to ensure that automated systems don’t inadvertently introduce new biases based on model training data.
For example, a LLM might:
Our Approach:
Handling resumes means handling personal data - names, contact information, employment history, and more. Ensuring that this data is processed securely and in compliance with privacy standards is of paramount importance.
All resume parsing and data processing happens entirely within our Google Cloud Platform (GCP) environment. We leverage GCP services such as:
These services comply with Google’s Cloud Service Terms, which include strong guarantees about data confidentiality and usage.
When processing sensitive information like resumes, data privacy is our highest priority. Our system is designed so that all inputs to the LLM are processed in a secure, isolated environment and are never stored beyond the immediate request. There are no feedback loops or mechanisms that send candidate data back to model training or fine-tuning pipelines.
Strict data segregation policies ensure your inputs are never shared with external services. These operational controls form the backbone of our privacy safeguards.
Complementing these measures, Google Cloud’s AI/ML Services contractually prohibit the use of customer data for training or fine-tuning models without explicit customer consent. This contractual commitment reinforces the privacy guarantees built into our infrastructure.
Together, these technical and legal safeguards ensure that your data remains private, isolated, and used solely for the intended AI processing - no data retention, no sharing, no model training.
In building our automated resume parsing pipeline, we set out to tackle a major challenge in recruiting: extracting structured, reliable data from unstructured, inconsistent resumes at scale. By leveraging modern NLP techniques, LLMs (via Vertex AI), and cloud infrastructure (GCP, BigQuery), we replaced slow and biased manual review with a scalable, auditable, and automation-friendly system.
Go ahead - test our parsing system. Submit your CV and experience recruiting that’s fast, fair, and format-proof.
Apply now & put us to the test!
Book a free 30-min consultation - see how AI turns unstructured CVs into structured, searchable talent data.
Large Language Models (LLMs) offer a powerful solution for handling resume parsing - but only when used thoughtfully. Success requires more than just calling an API. It involves engineering for validation, observability, maintainability, and fairness. By designing with these principles in mind, we turned LLMs from an experimental tool into a reliable system that integrates seamlessly into our hiring pipeline and supports better decision-making across the board.

Get to know us, discover our interests, projects and training courses.
.webp)




.avif)