How close is Google Cloud to offering a fully serverless Data Platform?
May 11, 2026
•
5
min read
Lesław Kułach
Introduction
In April 2026, at the time of this article's publication, Google Cloud updated several data analytics product names to be more descriptive. Throughout this article, we refer to these services using their previous names: Dataproc is now "Managed Service for Apache Spark," and Cloud Composer is now "Managed Service for Apache Airflow." These name changes reflect Google's commitment to clarity in their service offerings while the underlying functionality remains the same.
In recent years, the concept of "serverless data platform" has gained significant traction, especially in data infrastructure, as organizations seek to simplify operations, increase efficiency, and optimize costs. This article examines how close Google Cloud Platform (GCP) is to providing a fully serverless data platform to meet various data workflows and needs. By exploring scenarios like data ingestion, ETL processes, real-time processing, data warehousing, and machine learning, we’ll assess how well GCP enables organizations to focus on data-driven insights rather than cloud infrastructure management.
To address whether Google Cloud offers a truly serverless data platform, we must define two critical concepts:
What does serverless mean?
What is a Data Platform?
What Does Serverless Mean?
Serverless is a cloud computing model where users do not need to manage or interact with the underlying server infrastructure. The cloud provider, such as Google Cloud, handles infrastructure management. This model frees users from tasks like server setup, scaling, and maintenance, letting them focus on application functionality, business logic, and rapid deployment. Some key features of serverless services include:
No Infrastructure Management: Cloud providers handle all aspects of infrastructure, including scaling, patching, and monitoring, freeing users to focus solely on applications and logic.
Automatic Scaling: Serverless services dynamically scale based on demand. Resources are automatically allocated during peak loads and scaled back down when demand decreases, optimizing both performance and cost.
Pay-Per-Use Model: In serverless computing, users only pay for the compute time they use, rather than maintaining always-on infrastructure (pay-as-you-go pricing).
Faster Time to Market: By eliminating cloud infrastructure concerns, serverless platforms enable developers to quickly develop and deploy applications.
What Is a Data Platform?
Defining a data platform starts with understanding its core purpose and the key processes it enables. Essentially, a data platform serves as a key instrument for managing, processing, and analysing data within an organization. It empowers teams to harness the full potential of their data by streamlining critical processes.
To grasp the concept more effectively, it’s helpful to focus on the essential processing layers that a data platform typically supports. These include:
ETL/ELT (Extract, Transform, Load / Extract, Load, Transform). ETL (Extract, Transform, Load) and ELT processes are essential for preparing data for analysis and storage. These workflows involve systematically extracting data from diverse sources, transforming it to meet business or analytical needs, and loading it into target storage, such as data warehouses or data lakes. ETL/ELT pipelines can serve both real-time and batch processing needs, depending on the requirements.
Batch Data Processing. Batch data processing refers to the processing of large volumes of data at scheduled intervals, rather than in real-time. This approach is useful for data aggregation, summarization, and transformations where latency is not a concern. Batch processing ensures that substantial datasets are processed and ready for downstream analytics, machine learning, and business intelligence workflows.
Real-Time Data Processing. Real-time data processing enables immediate ingestion, analysis, and storage of data as it arrives, which is essential for low-latency use cases like monitoring systems, anomaly detection, and live data streaming. Real-time frameworks emphasize scalability and low latency to accommodate continuous data flows.
Data Lake Formation & Management. A data lake serves as a centralized repository storing structured, semi-structured, and unstructured data at any scale. Effective data lake management ensures governance, organization, and accessibility, allowing raw data storage until it’s needed for processing or analysis.
Data Warehousing & BI Reporting. Data warehousing provides a structured environment optimized for business intelligence (BI) and reporting needs, where processed and organized data is readily accessible for querying and analysis. BI tools then transform this data into dashboards, reports, and visualizations, supporting data-driven decision-making.
Orchestration and Scheduling. Orchestration and scheduling manage and automate workflows across data tasks, ensuring that processes run in the correct order and at specified intervals. By automating repetitive tasks, orchestration tools help streamline complex workflows, reduce operational overhead, and allow data teams to focus on higher-value activities.
Machine Learning Pipeline (MLOps). Machine learning pipelines, managed through MLOps (Machine Learning Operations), involve end-to-end processes for data preparation, model training, validation, deployment, and monitoring. By applying DevOps practices and principles to machine learning, MLOps promotes reproducibility, scalability, and lifecycle management of models in production. You can read more about ML lifecycle and MLOps practices in the article “The confusion about MLOps”.
Monitoring & Observability. Monitoring and observability provide real-time insights into the health, performance, and status of data workflows, which is essential for proactive management. These capabilities include tracking performance metrics, detecting anomalies, and identifying points of failure, allowing teams to address issues before they impact business operations. Advanced monitoring tools also enable automatic alerts, root-cause analysis, and streamlined debugging processes.
Data Cataloging and Metadata Management. Data cataloging and metadata management are critical for organizing, discovering, and understanding the data within a platform. A data catalog provides an inventory of available datasets, enriched with metadata that describes their structure, origin, usage, and quality. Metadata management ensures that data assets are well-documented, making it easier for users to find and trust the data they need.
Data Governance and Compliance. Data governance defines policies and controls to manage data consistently and securely. Compliance processes ensure that data handling meets regulatory and industry standards for privacy, security, and usage rights. These controls, including access control, lineage, and audit mechanisms, help organizations align with legal and ethical standards while building trust in data practices.
However, to fully understand how GCP supports a serverless data platform, we will explore some of the most common end-to-end processes.
Common End-to-End Data Platform Processes on Google Cloud
These end-to-end processes and workflows often combine multiple processing layers to achieve comprehensive data management and insight generation, with GCP offering a suite of tools to support each stage.
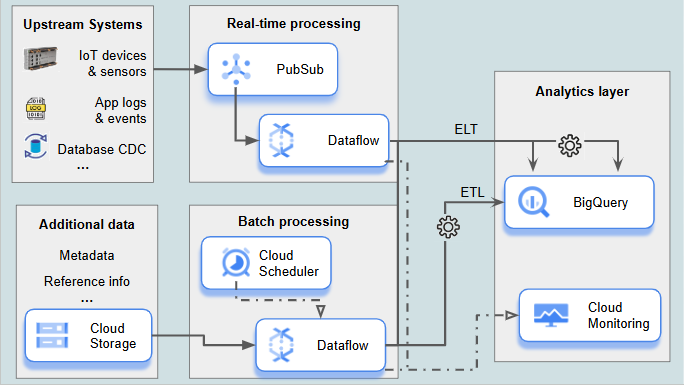
1. Data Ingestion and Transformation (ETL/ELT) Pipeline
Combined processing layers:
Real-Time Data Processing
ETL/ELT
Scheduling
Monitoring & Observability
Description: This pipeline focuses on ingesting data from multiple sources (for example IoT devices and sensors, app logs and events, DB CDC) and processing it in real-time to deliver immediate insights. The ETL/ELT processes enable systematic data extraction, transformation, and loading, primarily in real-time. Batch processing may complement this by ingesting additional data, such as metadata, dimensional data, or reference information, to enhance the accuracy and context of real-time analytics. Monitoring and observability allow teams to track pipeline performance and data flow health, while alerting policies ensure that teams are promptly notified about any pipeline failures, delays, or other anomalies.
Typical GCP Services:
Dataflow: Provides ETL/ELT processing in both real-time and batch modes.
Pub/Sub: Handles the ingestion of real-time streaming data.
Cloud Storage: Stages raw data or semi-structured data for processing.
BigQuery: Stores and queries transformed data, ready for analytics.
Cloud Monitoring: Monitors pipeline performance and data flow health. Enables alerting policies to notify teams of pipeline issues in real-time.
Conclusion on Serverless Capabilities:
All used GCP services are fully serverless so this solution can be fully implemented using Google Cloud's serverless platform.
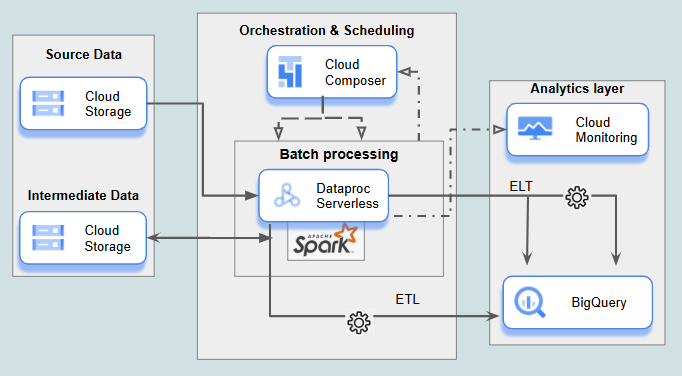
2. Batch Data Processing and Aggregation Pipeline
Combined processing layers:
Batch Data Processing
ETL/ELT
Orchestration and Scheduling
Monitoring & Observability
Description: Batch data processing handles large datasets at scheduled intervals, ideal for data transformations where real-time processing isn’t required. This approach is well-suited for large-scale data aggregations and analytics preparation tasks that require extensive compute power, such as those involving Spark or Hadoop. Automated scheduling ensures data processing occurs on time for downstream analytics workflows, while observability tools monitor performance and troubleshoot any issues.
Typical GCP Services:
Dataproc Serverless: Executes large-scale Spark and Hadoop jobs without the need to manage cluster infrastructure, ideal for complex batch processing and aggregation tasks.
Dataflow: (can be an alternative or supplement to Dataproc Serverless in certain cases) Performs scheduled batch processing with scalability and ease.
BigQuery: Stores and manages final, structured, processed data that is ready for analysis and querying.
Cloud Storage: Stores raw and intermediate datasets used in batch processing, often in various formats.
Cloud Composer: For orchestrating and scheduling batch processing tasks, ensuring workflows run consistently and supporting complex dependencies. Airflow’s flexibility and extensive support for customizations make it suitable for many use cases where more advanced orchestration is needed.
Cloud Workflows: (alternative to Cloud Composer) For simpler workflows spanning multiple services, Cloud Workflows offers a fully managed, serverless alternative to Cloud Composer, though it lacks some of Airflow’s more advanced orchestration features. For example Cloud Workflows does not natively support backfilling, that is a process of filling in missing data from the past in a new system that did not exist before, or replacing old records with new records as part of an update.
Cloud Monitoring: Observes processing performance, with tools to identify and respond to issues proactively.
Conclusion on Serverless Capabilities:
Most GCP services in this batch pipeline are serverless. However, Cloud Composer, while still under development, does not yet meet full serverless criteria.
Missing Serverless Features in Composer 2
Manual Infrastructure Management: while Composer 2 automates some aspects of the environment, users must still handle instance sizing, network configurations, and custom environment settings.
Idle Charges: Composer 2 environments incur charges for the entire environment even during idle periods, as resources such as workers, schedulers, and web servers are provisioned continuously. This limitation stems from Airflow's inherently stateful architecture, which makes scaling to zero difficult to achieve. By design, Airflow requires continuous operation of key components to maintain workflow states, scheduling information, and execution history. True serverless solutions scale down to zero during inactivity, ensuring cost efficiency, but Airflow's architectural requirements present challenges for this serverless principle.
Serverless Limitations in Composer 3
Cloud Composer 3 Scaling: to be more precise, Composer 3 scales down to a minimum number of resources, rather than scaling to absolute zero. It's important to note that the limitations described for Composer 2 remain the same for Composer 3
Custom Configuration: while Composer 3 reduces the need for manual configuration, there may still be specific use cases where custom configurations are required.
Infrastructure Management: The key difference between Composer 2 and 3 is that in Composer 2, the Google Kubernetes Engine (GKE) cluster is created in the customer's project, whereas in Composer 3, GKE is created in a Google-managed project. This makes Composer 3 more aligned with serverless principles by reducing infrastructure management responsibilities for users, though it doesn't eliminate the fundamental limitations stemming from Airflow's architecture.
While Cloud Composer (Airflow) is not fully serverless, recent advancements with Composer 2 and especially Composer 3 bring it closer to truly serverless functionality. Composer 3 introduces features that reduce manual management and optimize resource usage. However, it still requires a minimum number of resources to be running, even during periods of inactivity.
Serverless Alternatives:
For simpler orchestration needs, Cloud Workflows offers a fully managed, serverless alternative to Cloud Composer. For more complex workflows, consider using a combination of Cloud Run functions (formerly Cloud Functions) to trigger and manage specific parts of the pipeline.
3. Data Lake and Data Warehousing Architecture
Combined processing layers:
Data Lake Formation & Management
Data Warehousing & BI Reporting
Data Cataloging and Metadata Management
Data Governance and Compliance (cross-cutting)
Description: This architecture combines a data lake, where raw data from various sources is stored for scalability and flexibility, with a data warehouse for structured, analytics-ready data. Data is ingested from on-premises databases, cloud databases, APIs, and other sources, integrating seamlessly via Data Fusion. Data governance mechanisms ensure compliance, access control, and data lineage tracking across the data storage environments, enabling secure and consistent data handling throughout the platform.
Typical GCP Services:
Data Fusion: Provides a managed, code-free data integration service that connects on-premises databases, cloud databases, APIs, and other data sources.
Cloud Storage: Stores raw, unstructured, and semi-structured data in a scalable data lake format.
Dataplex: For data lake governance, cataloging, metadata management and lineage tracking.
BigQuery: For structured data storage and data warehousing.
Looker Studio: For building BI reports and dashboards.
IAM & Cloud DLP: For governance, access control, and data protection.
Cloud Audit Logs: For tracking access and changes across data assets.
Conclusion on Serverless Capabilities:
The architecture outlined above aligns well with the principles of a serverless data platform, offering significant advantages for modern data-driven applications. Google Cloud Platform (GCP) provides the foundation for a truly serverless experience across the entire data lifecycle.
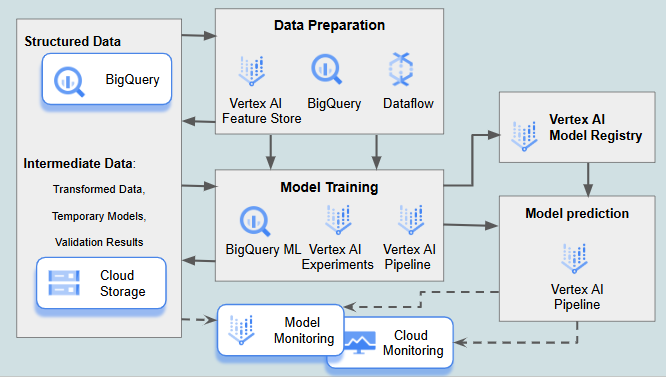
4. Machine Learning and Model Deployment Pipeline
Combined processing layers:
Machine Learning Pipeline (MLOps)
Data Warehousing & BI Reporting (as a data source)
Monitoring & Observability
Description: This pipeline prepares data for machine learning, trains and validates models, and deploys them to production. MLOps practices, integrated through the pipeline, enhance model reproducibility, scalability, and real-time monitoring for continuous model improvement.
Typical GCP Services:
BigQuery: For querying structured data to be used in training models.
Vertex AI: A comprehensive suite for building, training, deploying, and managing ML models, including specialized components like Vertex AI Experiments, Vertex AI Feature Store, Vertex AI Model Registry, and Vertex AI Model Monitoring for tasks such as model tracking, features managing, storing model, and monitoring performance over time.
BigQuery ML: A tool allowing data scientists to build and train models directly on BigQuery data
Cloud Storage: Primarily used for storing datasets and intermediate artifacts, such as transformed data, temporary models, and validation results. Its flexibility and scalability make it ideal for handling raw data and other non-final outputs required throughout the machine learning pipeline.
Vertex AI Model Registry: Designed for storing, versioning, and managing trained model artifacts. It ensures easy deployment and tracking of model versions, providing a centralized repository for production-ready models.
Dataflow: For data processing, enabling data transformation and enrichment before analysis.
Vertex AI Pipelines (part of Vertex AI): Automates end-to-end ML pipelines, ensuring efficient orchestration of data preparation, model training, evaluation, and deployment steps.
Vertex AI Model Monitoring: Tracks deployed model performance, detecting anomalies in predictions and changes in data distributions.
Cloud Monitoring: Complements Vertex AI Model Monitoring by offering broader observability across the pipeline, such as infrastructure metrics and alerts for supporting services (e.g., storage or data pipelines).
Conclusion on Serverless Capabilities:
GCP's suite of services aligns closely with the core principles of serverless computing. By automating Google cloud infrastructure management, scaling resources dynamically, and implementing a pay-per-use model, GCP significantly reduces the operational overhead associated with machine learning pipelines. Developers can focus on model development and experimentation, while GCP handles the underlying infrastructure.
5. Data Governance, Security, and Compliance Framework
Combined processing layers:
Data Governance and Compliance
Monitoring & Observability
Description: This framework ensures secure, compliant, and consistent data access across the organization. Data cataloging and metadata management facilitate data discovery, classification, and lineage tracking, supporting better governance and data quality assurance. Observability and monitoring enable proactive management of data policies, security events, and access logs, ensuring that data handling complies with industry and regulatory standards.
Typical GCP Services:
IAM: Defines and enforces access controls.
Cloud DLP (now part of Sensitive Data Protection): Detects and protects sensitive data.
Cloud KMS: Manages encryption keys to secure data.
Cloud Audit Logs: Tracks and monitors access, maintaining detailed compliance records.
Cloud Monitoring: Provides observability for security and compliance metrics.
Dataplex: Supports centralized governance with capabilities for data cataloging, metadata management, and lineage tracking across data assets.
Conclusion on Serverless Capabilities:
This framework leverages serverless services such as IAM, Cloud DLP, Cloud KMS, Cloud Audit Logs, and Cloud Monitoring, which require no infrastructure management and scaling is conducted automatically based on demand. Dataplex also provides centralized governance with minimal operational overhead, though it requires some configuration for setup. Overall, this architecture aligns well with serverless principles.
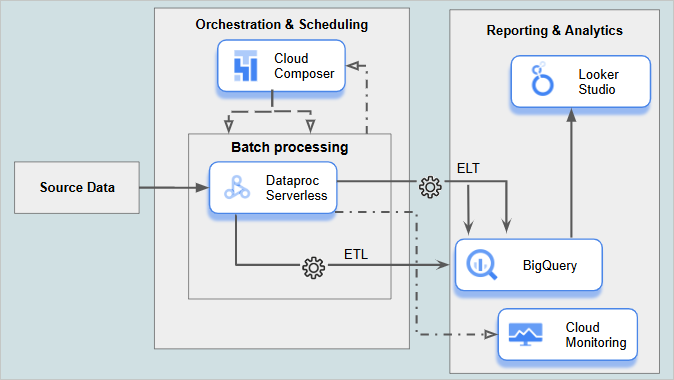
6. End-to-End Analytics and Reporting Pipeline
Combined processing layers:
ETL/ELT
Batch Data Processing
Data Warehousing & BI Reporting
Orchestration, Scheduling, and Monitoring
Description: This pipeline enables the ingestion, transformation, and storage of data for reporting and analytics. It combines batch ETL and real-time transformations, loading data into a data warehouse for BI and reporting. Orchestration and monitoring ensure reliability and performance at each stage.
Typical GCP Services:
Dataflow: For ETL and data transformation.
BigQuery: For centralized, structured data storage and analytics.
Looker Studio: For BI reporting and dashboarding.
Cloud Composer: For orchestrating and scheduling data processing tasks.
Cloud Workflows: (alternative to Cloud Composer) see the scenario “2. Batch Data Processing and Aggregation Pipeline”.
Cloud Monitoring: For tracking performance, troubleshooting, and monitoring data health.
Conclusion on Serverless Capabilities:
This pipeline is largely serverless, with services like Dataflow, BigQuery, Looker Studio, and Cloud Monitoring offering minimal infrastructure management, automatic scaling, and a pay-per-use model. However, Cloud Composer does not fully meet serverless criteria, as it requires Google Cloud infrastructure with ensuing costs and some management of underlying clusters. Cloud Workflows provides a fully serverless alternative for simpler orchestration needs, though Cloud Composer is often preferred for complex, dependency-driven workflows.
Conclusion
Google Cloud Platform has made remarkable progress in delivering a comprehensive serverless data platform that addresses the majority of enterprise data needs. By providing fully managed services across data ingestion, processing, storage, and analysis, GCP enables organizations to focus on extracting value from their data rather than managing infrastructure.
The platform's serverless capabilities excel in several key dimensions:
Automatic Scaling: Resources scale up to handle peak loads and down during periods of low activity, optimizing both performance and cost
Cost Optimization: Pay-per-use pricing ensures organizations pay only for actual resource consumption
Developer Productivity: Simplified deployment and management accelerate time-to-value for data initiatives
While GCP offers a robust serverless ecosystem, it's important to acknowledge certain limitations. Cloud Composer, based on Apache Airflow's inherently stateful architecture, cannot scale to zero during idle periods. Even with the improvements in Composer 3, which moves infrastructure to Google-managed projects, the service still maintains minimum resource requirements. For orchestration needs where true serverless functionality is essential, alternatives like Cloud Workflows may be more appropriate for simpler workflows.
Despite these specific constraints, GCP's commitment to serverless innovation is evident in continuous service enhancements and the introduction of new capabilities. For organizations seeking to modernize their data infrastructure, GCP offers a compelling path toward a fully serverless data platform. By leveraging these capabilities, businesses can accelerate innovation, improve agility, and focus their resources on extracting actionable insights from their data assets.
As Google continues to expand and enhance its serverless portfolio, we can expect further advancements that will close remaining gaps and reinforce GCP's position as a leader in serverless data platforms.
Share this post
GCP
Data Platform
Real Time Analytics
Data Engineer
Google Cloud
Lesław Kułach
Data Engineer
Experienced Data Engineer specializing in Google Cloud solutions, fluent in Python and SQL, with many years of experience in projects focused on data engineering as well as analytics and Machine Learning.
Related posts
Get to know us, discover our interests, projects and training courses.
Learn how telecom providers achieve real-time insights, 100% cost savings, and 30% higher engagement through Datumo’s advanced open-source data platform built for speed, scalability, and performance.
Azure IoT Edge enhances IoT systems by enabling local data processing on edge devices, reducing latency, bandwidth usage, and reliance on cloud computing while maintaining strong security and scalability. By supporting modular deployment, AI, and machine learning, it empowers real-time decision-making and automation, shaping the future of intelligent IoT solutions.
By clicking "View website", you agree to the storing of cookies on your device to enhance site navigation, analyze site usage, and assist in our marketing efforts. Providing consent is voluntary. You may refuse it or limit its scope by clicking "Preferences". For more information, please see our Privacy Policy.

.png)

.avif)

.avif)
